Non, je ne vais pas parler pas des voitures qui rentrent dans le sens de la largeur sur les places de parking mais d'une technologie présente sur les disques durs des ordinateurs depuis quelques années maintenant.
{kind=link}
Précisément S.M.A.R.T. — dont la version longue est Self-Monitoring, Analysis (and) Reporting Technology — est une technologie pour surveiller l'état du disque dur. C'est assez utile pour prévoir les pannes sur le disque dur avant qu'elles arrivent ou pour confirmer un problème.
La S.M.A.R.T. a donc deux principales utilités : faire de l'analyse et faire des rapports.
Accès aux informations S.M.A.R.T.
Sous Linux, l'outil smartctl permet d'obtenir toutes les informations du disque, si vous ne souhaitez pas lire la doc, utilisez la commande suivante :
# smartctl -a /dev/sda
Il existe aussi des utilitaires pour Windows ainsi que des utilitaires de diagnostic de disque (il y en a quelques-uns sur le UBCD − Ultimate Boot CD). Certaines cartes-mères sont aussi capables de remonter ces informations dans le BIOS.
La lecture des informations S.M.A.R.T. peut être effectuée lorsque le disque est en cours d'utilisation, sans aucun impact.
Self-Monitoring Analysis
La partie self-monitoring analysis permet de demander au disque dur : « effectue un self-test, pour savoir si tu es en bonne santé ». On distinguera deux principaux types de tests :
- Le court (environ 2 minutes) ;
- Le long (plusieurs minutes, voire plusieurs heures selon les disques).
Le plus court effectue un test des mémoires internes, vérifie le positionnement des têtes et très vaguement de la surface du disque (quelques zones bien précises). Les détails du test peuvent varier selon les constructeurs, mais principalement c'est ce qu'effectue le test rapide.
Le test long quant à lui, effectue un test court puis une lecture complète du disque (aussi appelée test de surface), c'est pourquoi sa durée est variable en fonction du disque.
Certains disques peuvent offrir d'autres modes de test, le conveyance (un mixte entre le long et le court) et le selective (qui permet de n'effectuer qu'une partie des tests).
Cet aspect de la S.M.A.R.T. ne s'utilise pas quotidiennement. En effet, les tests sont à lancer manuellement (le disque ne prend pas la décision d'effectuer un test de lui-même).
Sous Linux, il est possible d'utiliser le programme smartd pour effectuer de manière réguliére des tests (long ou short) et d'être prévenu (par mail) lorsqu’une erreur est signalée.
Dans tous les cas, une erreur qui serait signalée suite à un des tests d'analyse est très mauvais signe et je vous recommande vivement de faire des sauvegardes.
Comment vérifier ?
Sous Linux, il existe des utilitaires graphiques (tel que gnome-disk) mais le plus simple est encore la ligne de commande.
Pour effectuer un test court, on utilisera :
# smartctl -t short /dev/sda
Et pour effectuer un test long :
# smartctl -t long /dev/sda
La commande à utiliser pour voir les résultats des derniers tests est :
# smartctl -l selftest /dev/sda
Pour les autres systèmes d’exploitation, je ne sais pas répondre, mais il y a cette page sur Wikipédia qui liste des logiciels.
Reporting, a.k.a. Attributs
La partie la plus intéressante dans la vie du disque concerne la partie reporting.
Concrètement, il s'agit de différents attributs qui sont surveillés par le disque et mémorisés dans une mémoire non-volatile. Certains attributs sont communs à tous les disques, d'autres spécifiques.
Si on compare à un être humain, cela reviendrait à surveiller votre âge, le nombre d'heures où vous êtes eveillé, le nombre de fois où vous vous êtes coincé les doigts dans la porte, etc. Bref, tous les moments de votre vie qui pourraient aider à prévoir votre mort prochaine (oui, dit comme ça, ça fait un peu glauque).
C'est pourtant bien à ça que sert la partie reporting, surveiller le maximum de choses du disque pour estimer l'usure (et donc prévoir la mort). Pour aider dans cette tâche, le fabricant du disque définit des seuils critiques (généralement suite à des tests en laboratoire).
Afin de vous expliquer les attributs, je vais faire une comparaison avec une ampoule qui, d'après le constructeur :
- Peut être allumée 10 000 fois (cycle on/off) ;
- Peut tomber une fois par terre ;
- Est garantie pour fonctionner pendant 200 heures ;
- Peut fonctionner maximum 4 heures en continu.
Dans le tableau ci-dessous (qui est l'état S.M.A.R.T. de l'un de mes disques), on a plusieurs colonnes à lire :
- ID et Attribute Name (les deux sont synonymes) définissent le nom de l'attribut (ex, l'attribut Power_on ayant pour ID 9 correspond au nombre d'heures de fonctionnement) ;
- Value est une valeur dite normalisée de l'attribut qui est comprise entre 1 et 255 (ex : pourcentage de cycles on/off restant, 100 % quand c'est neuf, 90 % après 1 000 allumages, 40 % après 6 000, etc.) ;
- Worst correspond à la pire valeur (la plus basse) qu'il y a eu dans la case value (pour certains attributs sur un disque, la Value peut aussi augmenter − ici, cela pourrait être l'attribut correspondant au nombre d'heures en continu) ;
- Thresh correspond à la valeur critique définie par le constructeur (au bout de 9 950 cycles on/off, on décidera de lever une alerte) ;
- Type permet de savoir si l'attribut est annonciateur de mort ou d'usure (ex : 200 heures de fonctionnement est un signe d'usure puisque l'ampoule peut encore fonctionner après, tomber par terre est un signe de mort) ;
- When_Failed signifie simplement « est-ce que cet attribut est déjà passé sous le niveau critique thresh ? » ;
- Raw_value est la valeur brute de l'attribut (ex : l'ampoule a été allumée 3 000 fois).
Une fois que l'on a compris comment interpréter les valeurs, voici ce qu’il est très important de surveiller :
- 4 : Start_Stop_Count, correspond au décompte des cycles de mise en rotation (démarrage/arrêt) ;
- 5 : Reallocated_Sector_Ct, il s’agit du nombre de secteurs réalloués dans la zone de réserve ;
- 9 : Power_On_Hours, correspond au nombre d'heures de fonctionnement du disque ;
- 12 : Power_Cycle_Count, similaire à 4, mais compte les coupures électriques ;
- 193 : Load_Cycle_Count, compte le nombre de fois où les têtes ont été mises au repos ;
- 197 : Current_Pending_Sector, nombre de secteurs défectueux en attente de réallocation.
Une liste assez exhaustive est dispo sur la page Wikipédia.
Voici le résultat récupéré sur l’un de mes disques durs :
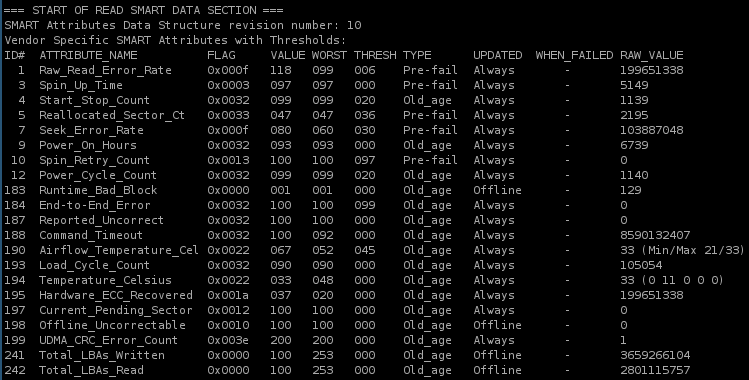
Voici ce que l’on peut en déduire :
- Ce disque n’a eu que peu de redémarrages complets (1 140 fois), et avec la valeur de 4 on en déduit qu’il ne passe jamais en veille.
- La valeur 193 est relativement haute par rapport au nombre d’arrêts, mais sans risque immédiat (la valeur maximale constructeur est généralement autour de 500 000).
- Il a fonctionné 6 700 heures au total (en règle générale, un disque a une durée de vie de 50 000 heures).
- Il possède un bon nombre de secteurs défectueux (plus de 2 000), étant donné le peu d’heures de fonctionnement cela signifie que la surface du disque a probablement un défaut ou que les conditions d’utilisation sont loin des recommandations du constructeur (qui va donc provoquer une usure plus rapide). Le seul point positif, c’est qu’il n’y a plus de secteur en attente de réallocation.
- Le point précédent se voit aussi confirmé par les attributs 1 et 7, le premier indiquant des erreurs de lecture, le deuxième un problème lors du positionnement des têtes.
En bref, si j’étais vous, avec un disque qui annonce des informations comme ça, je commencerais à vérifier que mes sauvegardes sont bien exploitables…